참고 링크: From zero to 50 million uploads per day: scaling media at Canva
From Zero to 50 Million Uploads per Day: Scaling Media at Canva - Canva Engineering Blog
The evolution of media persistence during hypergrowth at Canva
www.canva.dev
개요
최근 대규모 시스템에서의 데이터베이스 확장성에 대한 고민을 다룬, Canva 블로그 아티클을 읽었습니다. 이 글에는 대규모 서비스에서 마주칠 수 있는 문제 상황과 이를 해결해나가는 과정이 잘 담겨 있어 인상 깊었는데요, 이를 한 번 저만의 언어, 청사진으로 정리해놓고자 하여 이 글을 작성합니다.
이번 포스트에서는 개발자들이 흔히 채택하는 AWS RDS(MySQL) 기반 아키텍처가 큰 트래픽 성장(미디어 10억 개 돌파)을 마주했을 때 어떤 한계에 부딪히는지, 그리고 이를 글로벌 스케일의 서비스를 관리하는 개발팀에서 극복하기 위해 어떤 조치를 하는지 다루고 있습니다.
대규모 서비스에서의 RDBMS의 한계
Canva 역시 초기에는 DB 아키텍처를 AWS RDS에서 호스팅되는 MySQL로 시작했습니다. Canva의 서비스가 점점 성장하고 트래픽이 증가하더라도, 처음에는 더 큰 인스턴스로의 Scale up, Read Replica를 추가하는 Scale out을 통해 증가하는 수요를 충당할 수 있었습니다.

하지만 저장된 미디어 수가 10억 개에 육박하면서 RDBMS의 태생적인 한계가 드러나기 시작했습니다.
먼저, 스키마 변경 작업에만 며칠이 걸리기 시작했습니다. DDL 작업 시 발생하는 Lock과 성능 저하 때문에, 정상적인 사용자 트래픽을 처리하면서 스키마를 변경하는 것은 불가능에 가까웠고, 이에 Live Migration을 진행하기가 어려웠습니다. 반대로 서비스를 중단한 상태에서 스키마 마이그레이션을 진행하자니, 최대 6주가 소요되는 문제가 있었습니다.
또한, Replication Lag가 증가하는 문제가 발생하고 있었습니다. 당시 사용하던 MySQL 5.6 버전에서는 레플리카 복제 속도에 제한이 있었는데, Master에 실시간으로 반영되는 변경 사항이 점점 많아지면서 Read Replica에 변경사항이 반영되는 속도가 이를 따라가지 못하며 병목이 발생하기 시작했습니다.
마지막으로, RDS MySQL이 지원하는 EBS Volume의 최대 크기인 16TB 한계에 도달하는 물리적인 한계도 발생하였습니다.
이에 Canva 개발팀은 새로운 아키텍처가 필요하다고 판단, 마이그레이션 작업을 준비하기 시작했습니다.
마이그레이션 사전 준비 (MySQL 최적화)
바로 당장 시스템 아키텍처를 갈아엎을 수는 없었기에, Canva 개발팀에서는 아키텍처 마이그레이션과는 별개로 MySQL의 한계를 우회하기 위해 다양한 최적화 기법을 도입하기 시작하였습니다.
먼저 가장 자주 수정되는 스키마 영역을 JSON 타입 컬럼으로 마이그레이션했습니다. 이를 통해 무거운 ALTER TABLE 없이도 유연하게 데이터 구조를 변경할 수 있게 되어 DDL 작업의 부담을 크게 낮췄습니다.
또한 쿼리 성능을 전반적으로 개선하기 위한 작업들을 진행하였습니다. 무거운 조인(JOIN)을 줄이기 위해 일부 테이블을 비정규화하였고, 외래 키 제약 조건을 제거한 뒤, 데이터에 대한 정합성을 애플리케이션 레벨에서 책임지도록 하였습니다. 외래 키가 존재하면 자식 테이블에 INSERT/UPDATE가 발생할 때마다 부모 테이블을 조회하여 무결성을 검사하기 때문에, 이 작업을 경량화하고자 하였습니다. (e.g. 주문 생성 시, fk인 user_id가 유저 테이블에 실재하는지 조회).
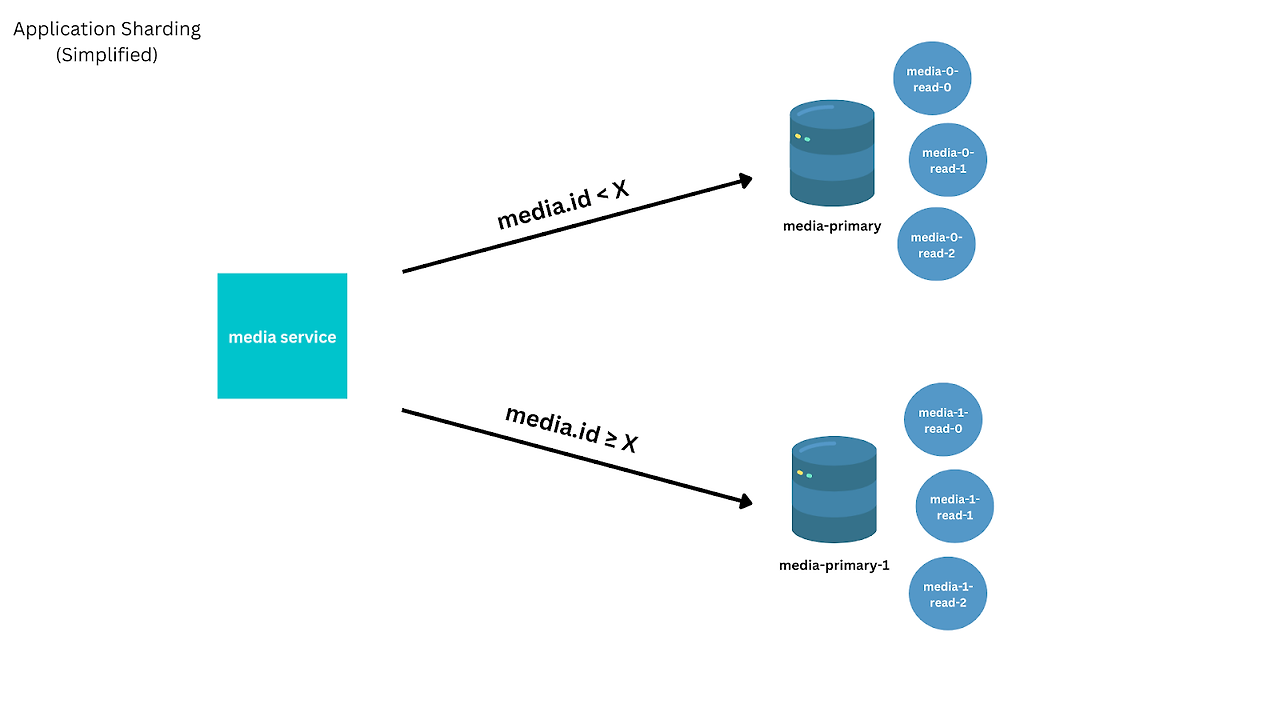
마지막으로, 샤딩 솔루션을 구축했습니다. 특정 ID 기반의 단건 조회는 최적화가 잘 되었지만, 모든 미디어를 나열하는 등의 쿼리에서는 여러 샤드에 쿼리를 병렬로 던지고 결과를 모으는 Scatter-Gather 패턴을 사용해야 했기에 여전히 비효율이 존재했습니다.
DynamoDB로의 마이그레이션
이렇게 1차적인 최적화 이후, 근본적인 확장의 한계를 해결하고자 Canva 개발팀은 AWS의 NoSQL 솔루션인 DynamoDB로 마이그레이션을 진행하였습니다. 이 마이그레이션에서의 핵심 사안은 초당 수천 건의 요청이 들어오는 라이브 서비스에서 10억 개의 미디어 데이터를 다운타임 없이 안전하게 넘길 것인가? 였습니다.

Canva 팀에서는 데이터 매핑에 대한 완전한 통제권을 쥐고 상황에 맞춰 점진적으로 이관하는 것을 원했기 때문에, AWS DMS 같은 마이그레이션 툴이나 애플리케이션 레벨에서의 Dual write를 선택하지 않고 자체적인 마이그레이션 파이프라인을 구축했습니다.

참고: 애플리케이션 레벨의 Dual Write 방식이란?
백그라운드 워커에서 마이그레이션 대상 DB로 데이터를 이관함과 동시에 Dual Write를 일정 기간동안 수행하고, 조금씩 트래픽을 마이그레이션 대상 DB쪽에서 처리하도록 점진적으로 전환한다고 합니다. 이 과정은 당근 마켓에서의 MSA 전환기에서 자세히 볼 수 있으니 관심있으신 분은 확인해보시면 도움이 될 것 같습니다.
Canva 개발팀에서는 기존 MySQL 클러스터의 부하를 최대한 빨리 줄이는 것을 1순위 목표로 설정하였습니다. 미디어 데이터에는 "최근에 생성되거나 수정된 데이터가 가장 빈번하게 조회된다" 는 패턴이 있었고, 이를 바탕으로 새롭게 생성, 변경되거나, 최근 읽기 요청이 들어온 미디어부터 우선적으로 DynamoDB로 마이그레이션하여 MySQL로 향하는 트래픽을 빠르게 덜어내고자 하였습니다.
나머지 과거 데이터들은 스캐닝 프로세스를 통해 처리했습니다. 이 역시 무작위가 아니라 가장 최근에 생성된 데이터부터 역순으로 스캔하며, 시스템에 무리를 주지 않도록 상대적으로 낮은 우선순위의 큐를 통해 DynamoDB로 비동기 복제되도록 설계했습니다.

본격적인 전환 전, 데이터 정합성을 검증하기 위해 '이중 읽기 및 비교' 프로세스를 도입했습니다. 실제 클라이언트 요청이 들어오면 MySQL과 DynamoDB 양쪽 모두에서 데이터를 읽어와 결과를 비교하는 Shadow Testing을 거쳤습니다. 여기서 발견된 복제 로직의 버그들을 모두 해결한 후에야 DynamoDB를 주 읽기 저장소로 승격시켰고, 아직 복제가 완료되지 않은 과거 데이터에 한해서만 MySQL로 Fallback 처리하여 정합성과 안정성을 모두 잡았습니다.

결과적으로 마이그레이션을 통해 Canva는 사용자 수가 3배 이상 폭증하는 상황에서도 트래픽을 무리 없이 감당했으며, 오히려 기존 AWS RDS 클러스터를 유지할 때보다 인프라 비용을 절감하는 효과를 얻었습니다.
Canva 개발팀의 회고
하지만 마이그레이션이 무조건 이점만 가져다 주었을까요? Canva 개발팀에서는 DynamoDB와 같은 NoSQL이 무한한 확장성을 주었지만, RDBMS가 주던 편리함도 함께 앗아갔다고 평가하였습니다.
먼저, 스키마 변경이나 과거 데이터 Backfill 작업을 할 때 이전보다 훨씬 더 엄격한 테스트와 복잡한 병렬 스캔 코드가 필요해졌습니다. 가령 과거 데이터 10억 건에 값을 채워 넣어야 한다고 가정하면, RDB에서는 UPDATE media SET is_processed = false WHERE created_at < '2023-01-01'; 같은 SQL 쿼리 한 줄로 변경을 처리할 수 있습니다. DynamoDB에는 다중 레코드 업데이트 쿼리가 존재하지 않기 때문에, 어플리케이션 수준에서 여러 워커 스레드가 병렬로 데이터를 Full Scan하고, 라이브 서비스 트래픽에 영향이 가지 않는 수준에서 Rate Limiter을 통해 백필을 수행해야 합니다.
또한, MySQL 시절처럼 복제본에 임시 SQL 쿼리를 날려 데이터를 분석하는 것이 불가능해져, 이를 해결하기 위해 별도의 CDC(Change Data Capture) 파이프라인을 구축해야 했습니다. 가령 기획자나 데이터 분석가가 "최근 일주일 동안 업로드된 영상 중, 10초 이상인 미디어의 비율을 뽑아주세요" 같은 요청을 한다면 RDB에서는 Read Replica를 하나 띄워서 복잡한 쿼리를 마음껏 날려도 상관없었습니다. DynamoDB에서는 이러한 운용이 어렵기 때문에 데이터 분석 수요를 충당하기 위해, 분석에 특화된 데이터 웨어하우스(e.g. AWS Redshift)를 별도로 구축하고, 운영 DB의 데이터 변경 사항을 웨어하우스로 스트리밍하는 파이프라인이 추가로 구축되어야 했습니다.
최종적으로, Canva 개발팀에서는 같은 문제를 겪게 된다면 NewSQL 제품을 고려해볼 것 같다고 회고하였습니다.
Canva 개발팀이 고려했던 NewSQL은 무엇일까? 주류 기술일까?
이 글을 읽고 가장 기억에 남았던 부분은 Canva 엔지니어들이 다시 돌아간다면 강력하게 고려하겠다고 언급한 NewSQL이었습니다. 일반적으로 우리가 DB를 선택함에 있어 선택지에 오르는 RDBMS나 NoSQL은 자주 등장하는 개념이었지만, NewSQL은 제게는 다소 생소하였습니다. 그렇다면 NewSQL은 구체적으로 무엇이고 현재 어떤 위치에 있을까요?

NewSQL(e.g. TiDB, CockroachDB, Google Cloud Spanner)은 NoSQL처럼 수평 확장이 자유로우면서도, 기존 RDBMS의 엄격한 트랜잭션(ACID)과 SQL 인터페이스를 그대로 유지하는 DB입니다. 이렇게 좋은 점만 가득하다면 우리가 왜 NewSQL을 자주 접할 수 없었을까요? Reddit, LinkedIn과 같은 커뮤니티에서 개발자들은 그 이유를 복잡성과 Over Engineering이라고 이야기합니다.
먼저 NewSQL은 내부적으로 기존 RDBMS와 작동 방식이 완전히 다르기 때문에, 내부 분산 아키텍처와 트랜잭션 격리 수준을 완벽하게 이해해야 하는, 러닝 커브가 매우 높은 기술이라고 합니다. 범세계적인 규모의 서비스가 아니라면, 잘 튜닝된 MySQL에 Read Replica를 추가하고, Redis로 캐싱하는 스탠다드한 아키텍처로도 충분히 대응이 가능하기 때문에 대부분의 개발자에게는 생소하게 다가오는 것이죠.
후기
이 글에서는 기술 선택에서 오는 딜레마가 잘 드러나 있었던 것 같습니다. 우리 엔지니어들은 다양한 기술의 바다에서, 내 상황에 가장 적절한 것을 선택하기를 반복합니다. 기존에 사용하던 기술이 한계에 도달하여 새로운 기술으로 나아간다면, 그 기술의 복잡성이 다시 우리의 발목을 잡게 됩니다.
Canva의 사례가 정확히 이를 보여줍니다. RDBMS의 한계를 벗어나고자 NoSQL을 선택했지만, 그 대가로 DB가 알아서 처리해주던 join, 트랜잭션, 데이터 스캔을 포기해야 했습니다. 결국 그 빈자리는 개발자가 직접 짠 분산 병렬 스캔 코드와 복잡한 실시간 CDC 파이프라인 구축이라는 애플리케이션 레벨의 복잡도로 고스란히 되돌아왔습니다.
팀 내에서 리팩토링을 기획하거나 시스템 설계를 논의할 때도 늘 비슷한 문제를 직면하곤 합니다. 열정이 많은 개발자들은 개인의 흥미로, 혹은 문제를 해결하기 위해 화려한 신기술이나 거창한 아키텍처를 도입하고 싶어하지만, 결국 우리는 이 새로운 기술이 가져올 트레이드오프와 운영 복잡성을 온전히 책임질 수 있는가?를 묻지 않을 수 없습니다. 현재 우리가 감당할 수 있는 적정선을 찾고 리스크를 통제하며 점진적으로 나아가는 것이야말로 엔지니어링에서 가장 중요한 것이 아닐까 생각합니다.